Having slow queries, management complexity and high cost nightmares?
Forget about data warehouse and analytics infrastructure, let us take care of it for you
What exactly is SlicingDice?
SlicingDice is a Full-Service Data Warehouse and Analytical Database as a Service. We know engineers need to load, store, query and visualize data, but they hate having to manage complex data infrastructure, so we do it for them. All they have to do is insert and query billions of real-time (stream) and historical (batch) data, static or time-series, without any server management.
We speak your language!
Do you want to insert your data using our REST API and query it with standard SQL? Sure, why not?
SlicingDice provides full flexibility for you to choose how you want to insert and query your data.






And their languages too.
Any data you store on SlicingDice can be accessed using many BI platforms and visualization tools.









Yes, you can trust your business to us!
SlicingDice powers thousands of OLAP databases with lots of data coming from:
These two metrics below are a good indication that we can handle your BIG DATA.
179 Billion
Insertion requests since January
1,2 Billion
API calls in the past 24h
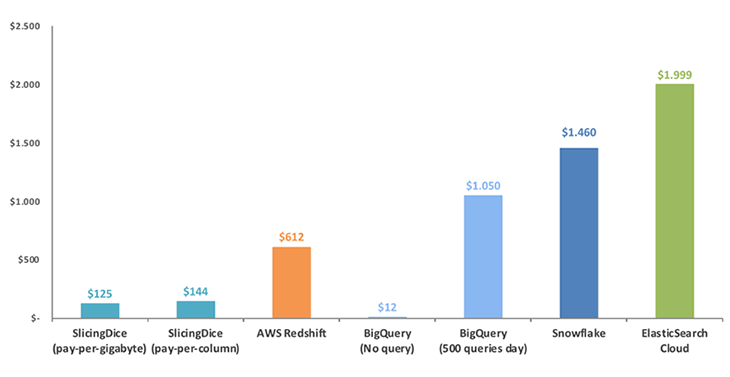
Simple, flexible and fair pricing!
We give you the flexibility to select between two different pricing models, price-per-gigabyte stored or pay-per-column. If you are not sure what is the best option for your use case, don't worry, our platform can automatically select the cheapest one for you. Amazing, right?
How are we better for your data needs?
We exist to empower you in using data to extract insights and opportunities for your company.
To do that we must free you from all the data warehouse administration workload, so you can concentrate on simply storing and querying your data.
Simple to learn. Nothing to manage. Start inserting and querying your data in less than 5 minutes.
No matter your data size or query complexity, it will always be fast. Any query under 10 seconds.
Transparent and unbeatable prices. Totally pay-per-use. No commercial or technical lock-in, you can leave at any time.
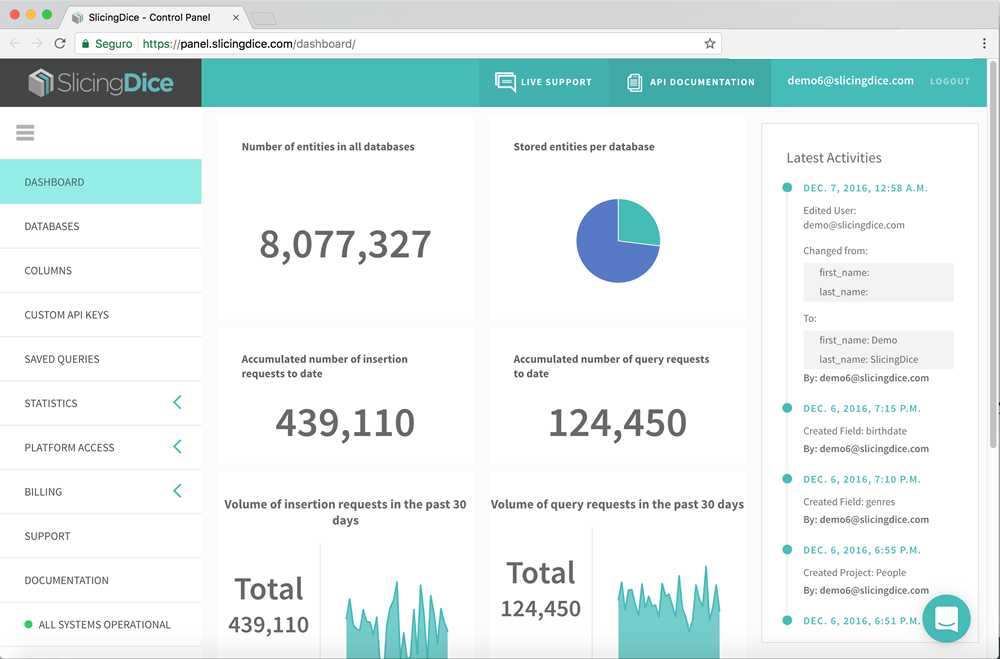
SlicingDice Control Panel
We know how boring it is to create an account in every new service that appears and we don't want you to go through this hassle just to check our service. By clicking the button below you can get full access to our control panel demonstration using a demo account and data. No sign up needed.
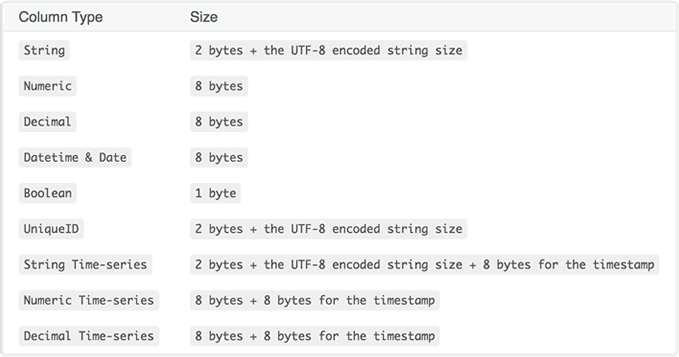
Pay-per-gigabyte
By using the pay-per-gigabyte pricing model you only will pay for the storage space used to store the data on your SlicingDice database. This table on the right describes how we calculate the total size of your database, according to each data type you store on it. Null values for any column type are calculated as 0 bytes. Repeated values are calculated per entry, so a Numeric column with 4 entries counts as 32 bytes. Important: Different from most of our competitors, we don't charge anything for processing the queries you make! Amazing, right?
Pay-per-gigabyte Prices
Monthly spend = Sum of Gigabytes stored x Cost per Gigabyte + Insertion Load Plan + Query Load Plan.
Example: $75.00 per month = 100 GB x $0.25 ($25.00) + normal query load ($0.00) + high insertion load ($50.00)
Presenting the next-gen user
From 1 to 10,240 Gigabytes (10 Terabytes)
US$ 0.25 per GB
More than 10,240 Gigabytes
Contact us for big volume discounts.
Price per Query Processed
US$ 0.00 (TOTALLY FREE)
At SlicingDice you don't pay anything for making queries, just for the storage space it takes to store your data.
Data Insertion Load Plans - Monthly Fee
Normal - Up to 600 Insertions Per Minute
FREE
High - Up to 6,000 IPM
US$ 50.00
Mega - Up to 30,000 IPM
US$ 250.00
Ultra - Up to 60,000 IPM
US$ 500.00
More than 60,000 IPM
Contact us for big volume discounts.
Query Load Plans - Monthly Fee
Normal - Up to 60 Queries Per Minute
FREE
High - Up to 300 QPM
US$ 50.00
Mega - Up to 600 QPM
US$ 100.00
Ultra - Up to 6,000 QPM
US$ 1,000.00
More than 6,000 QPM
Contact us for big volume discounts.
Frequently Asked Questions
Contact us on the online chat if you couldn't find an answer to your question in the following list.
Why is SlicingDice so cheap?
Because we store your data in a different way and strongly leverage data compression, allowing us to have much lower costs.
Can I get free access to test the service?
Yes. Absolutely! On this documentation page you can find all the details and instructions for testing SlicingDice for free.
What type of data can I store on SlicingDice?
You can store string, integer, decimal, boolean, date and datetime (timestamp) values. On this documentation page you can find all the data types supported by SlicingDice.
How many columns can I have?
As much as you need, there is no limitation. Just keep in mind that on the Pay-per-column pricing model you pay for each column, but doesn't matter how much data you store for it.
How much data can I store?
As much as you need, there is no technical limit. Remember that Pay-per-gigabyte pricing model charges per storage, but Pay-per-column does not.
Can I change the pricing model for my database?
Yes, you can change the pricing model for a database at any time. Once you make the change, it will be considered for the next billing cycle.